微服务架构下使用Nginx变量对应用程序进行性能追踪[转]
使用变量来对应用程序性能进行管理
变量是NGINX配置的一个重要且有时被忽视的方面。 Nginx 有大约150个变量可用,Nginx 变量可用来方便每个部分的配置。 在本博客中,我们讨论如何使用NGINX变量来进行 应用程序跟踪 和 应用程序性能管理(APM) ,重点是发现应用程序中的性能瓶颈。 这篇文章适用于开源的 NGINX 软件和 NGINX Plus。 为了简洁,我们将参考NGINX Plus,除非两个产品之间有差异。
应用程序交付环境
在我们的示例应用程序交付环境中,NGINX Plus作为我们应用程序的反向代理。 应用程序本身包括一个Web前端,后面是多个微服务。
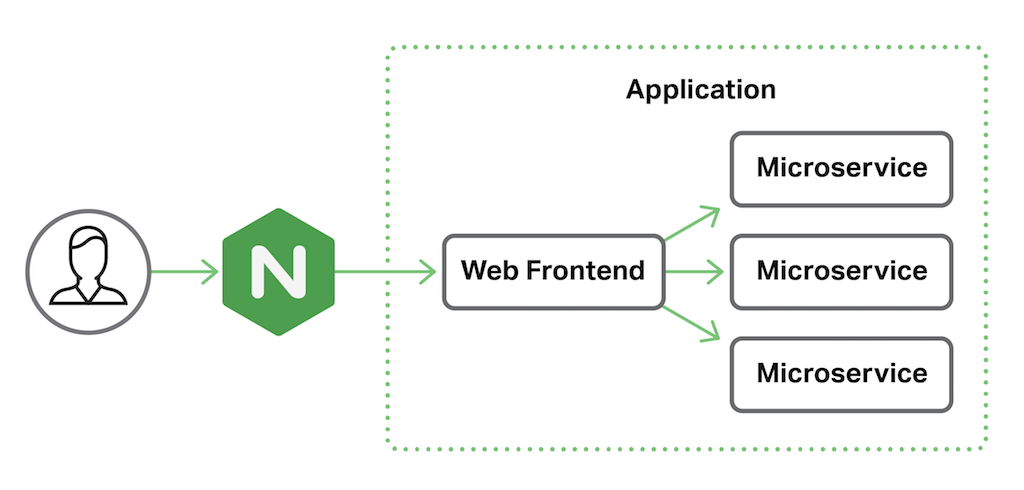
跟踪端到端(End‑to‑End)请求
NGINX Plus R10(和NGINX 1.11.0)引入 $request_id 变量,它是随机生成的32个十六进制字符串,在每个HTTP请求到达时自动分配给它们(例如444535f9378a3dfa1b8604bc9e05a303)。 这个看似简单的机制解锁了一个强大的工具,可用于跟踪和故障排除。 通过配置NGINX Plus和所有后端服务传递$request_id值,您可以跟踪每个请求端到端。 这个示例配置是为我们的前端NGINX Plus服务器。
upstream app_server {
server 10.0.0.1:80;
}
server {
listen 80;
add_header X-Request-ID $request_id; # Return to client
location / {
proxy_pass http://app_server;
proxy_set_header X-Request-ID $request_id; # Pass to app server
}
}
要配置NGINX Plus进行请求跟踪,我们首先定义 upstream 块中应用程序服务器的网络位置。 为了简单起见,我们在这里只显示一个应用程序服务器,但通常使用几个应用程序服务器来实现高可用性和负载平衡。
server块定义了NGINX Plus如何处理传入的HTTP请求。 listen指令告诉NGINX Plus侦听端口80,但生产环境配置通常使用SSL/TLS来保护传输中的数据。
add_header指令将$request_id值作为响应中的自定义header头发送回客户端。 这对于测试以及生成自己的日志(如移动应用程序)的客户端应用程序非常有用,以便客户端可以精确匹配服务器的错误日志。
最后,location 块应用于整个应用程序空间(/),proxy_pass指令简单地代理所有请求到应用程序服务器。 proxy_set_header指令通过添加传递给应用程序的HTTP头来修改代理请求。 在这种情况下,我们创建一个名为X-Request-ID的头,并为其分配$request_id变量的值。 因此,我们的应用程序接收由NGINX Plus生成的request ID。
记录端到端的$request_id
我们的应用程序跟踪的目标是确定请求处理生命周期中的性能瓶颈,作为应用程序性能管理的一部分。 我们可以通过在处理过程中记录重要的事件来做到这一点,方便我们以后分析它们的异常或不合理的延迟。
配置NGINX Plus
我们从配置前端NGINX Plus服务器开始,将$request_id包含在用于access_trace.log文件的自定义日志记录格式trace中。
log_format trace '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" "$http_user_agent" '
'"$http_x_forwarded_for" $request_id';
upstream app_server {
server 10.0.0.1;
}
server {
listen 80;
add_header X-Request-ID $request_id; # Return to client
location / {
proxy_pass http://app_server;
proxy_set_header X-Request-ID $request_id; # Pass to app server
access_log /var/log/nginx/access_trace.log trace; # Log $request_id
}
}
配置后端应用程序
将 Request ID 传递到我们的应用程序有时也会用到。 在这个例子中,我们有一个由uWSGI管理的Python应用程序。 让我们修改应用程序入口点,以获取Request ID 作为日志变量。
from uwsgi import set_logvar
def main(environ, start_response):
set_logvar('requestid', environ['X_REQUEST_ID'])
然后我们可以修改uWSGI配置,将Request ID包含在标准日志文件中。
log-format = %(addr) - %(user) [%(ltime)] "%(method) %(uri) %(proto)" %(status)
%(size) "%(referer)" "%(uagent)" %(requestid)
通过这种配置,我们现在可以生成日志文件,这些文件可以跨多个系统,我们可以通过requestid来查看我们单次request的调用链。
来自NGINX的日志示例:
172.17.0.1 - - [02/Aug/2016:14:26:50 +0000] "GET / HTTP/1.1" 200 90 "-" "-" "-" 5f222ae5938482c32a822dbf15e19f0f
来自应用程序的日志示例:
192.168.91.1 - - [02/Aug/2016:14:26:50 +0000] "GET / HTTP/1.0" 200 123 "-" "-" 5f222ae5938482c32a822dbf15e19f0f
通过将 Request ID 字段与事务匹配,Splunk 和 Kibana 之类的工具允许我们识别性能瓶颈。 例如,我们可以搜索花费两秒钟以上时间完成的请求。 然而,在常规时间戳中的默认时间精度为一秒不足以用于大多数真实环境的分析。
高精度时序
为了准确地测量端到端请求,我们需要具有毫秒级精度的时间戳。 通过在日志条目中包括$msec变量,我们在每个条目的时间戳上获得毫秒的精度。 向应用程序日志添加毫秒时间戳允许我们查找花费 本该不超过200毫秒完成,但却花了2秒的请求。
但是即使这样,我们也没有得到全部的图片,因为NGINX Plus只在处理每个请求结束时写入$msec时间戳。 幸运的是,有几个其他NGINX Plus定时变量,毫秒精度,让我们更深入地了解处理本身:
$request_time– 完全请求时间,从NGINX Plus从客户端读取第一个字节,并在NGINX Plus发送响应主体的最后一个字节时结束$upstream_connect_time– 花费在与upstream服务器建立连接的时间$upstream_header_time– 建立到upstream服务器的连接和接收响应头的第一个字节之间的时间$upstream_response_time– 建立到upstream服务器的连接和接收响应主体的最后一个字节之间的时间
有关这些时序变量的详细信息,请参阅[使用NGINX日志记录应用程序性能监视](Using NGINX Logging for Application Performance Monitoring)。
我们可以扩展我们的log_format指令,将所有这些高精度定时变量包含在我们的跟踪日志格式中。
log_format trace '$remote_addr - $remote_user [$time_local] "$request" $status '
'$body_bytes_sent "$http_referer" "$http_user_agent" '
'"$http_x_forwarded_for" $request_id $msec $request_time '
'$upstream_connect_time $upstream_header_time $upstream_response_time';
使用我们首选的日志分析工具,我们可以提取变量值并执行以下计算,以了解NGINX Plus在连接到应用程序服务器之前处理请求的时间:
NGINX Plus processing time = $request_time - $upstream_connect_time - $upstream_response_time
我们还可以搜索$upstream_response_time的最高值,查看它们是否与特定URI或上游服务器相关联。 然后可以进一步检查具有相同请求ID的应用程序日志条目。
结论
利用新的$request_id变量和一些毫秒精度的时间变量可以提供对应用程序性能瓶颈的深入了解,提高应用程序性能管理,而无需使用什么重量级代理和插件。
【原文】:https://www.nginx.com/blog/application-tracing-nginx-plus/